Practical approaches to fine-grained sandboxing on the server
Problem: execute arbitrary user-supplied code.
How do we do that, securely?
Here’s the same problem: write a server that handles user input. I.e., every server in the world. How do we do that, securely?
In this post, we’re going to focus on “fine-grained” server-side sandboxing. Browser sandboxing will be the focus of another post.
The case for per-request sandboxing
Why do you care about running arbitrary user input? You’re not building the next replit. You’re just building a normal LOB CRUD web application. Maybe you’re using Django, Rails, go, or some Next.js server rendering.
You think your application is relatively secure, and you’ve covered your OWASP top ten bases—no SQLi/XSS/XSRF/etc. But how do you know your application is “secure”? Perhaps you’re not blindly calling eval() on user input anywhere, but you’re doing calling into some popular C image optimization library on a user-uploaded image file. Risky, risky.
CS101 says: code == data. Any data can become “code”, either expectedly or unexpectedly.
One thing you might have read about is sandboxing. So you run your application in a sandbox. (We’re ignoring what this means, and what a sandbox actually is.) You can isolate your application from the rest of the OS, for instance. Even if there’s some heap overflow, you’ll be able to rest easy your host isn’t compromised.
This is the conventional use case for sandboxing. Another example: you downloaded some application from the interwebs and want to try it out, but without letting it read random files or mess up your system. (Or similarly: you downloaded a PDF and want to open it up.)
In all these cases, you are protecting what’s outside the sandbox—your “host” / “platform” / “OS” / etc.—from what’s inside. Is that really what you care about?
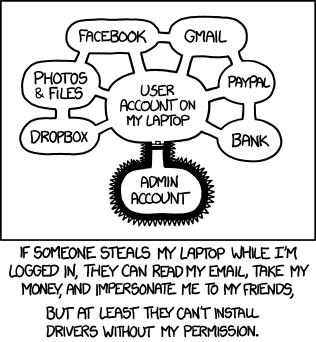
What you typically care about is confidentiality and integrity of your user’s data. As another example besides calling into native code—how do you know you don’t have any data structures shared across requests that users might be able to key into?
Ideally you can sandbox the requests from each other!
Sandboxing is sometimes thought of as a relatively niche need. But really, it’s applicable in far more places than it gets airtime today. We are still in the stone ages—in an ideal future state of the world, most server software should routinely employ sandboxing and isolation on most things they do.
In this typical web application server example, the server serves requests from many users in the same process—with no isolation from each other. Olden process-isolated CGI scripts excepted—but simply running separate processes doesn’t necessarily help with anything.
Much attention has been spent on isolating the workloads (across all users, as a whole) from the underlying platform (privilege escalations, etc.), and from other services/parts of the stack. This is the industry standard.
In server applications, you frequently want requests to be sandboxed from each other. Sandboxing at this fine a granularity is not typically done.
In that sense, browsers are ahead of servers. Sandboxing routinely happens on a fine-grained level within a browser—and even to some extent within a browser tab, with various execution contexts having more limited or less limited access to things. Browsers are an extremely attractive target, and significant attention has been spent on securing the client, and doing so efficiently so you’re not spinning up a VM per origin.
I wanted to braindump some collection of approaches I’ve accumulated around this topic for some time, and try to better organize them on paper.
General approaches
Virtual machines
Virtualization is powerful, and at a level of abstraction in the stack that has by now earned a high amount of trust. Hypervisors let each guest OS think it has the machine.
Techniques like dynamic binary translation let you ensure that the set of sensitive privileged instructions trap to the hypervisor and get emulated. This has to deal with things like jumps-to-register-values, self-modifying code, etc., but we can rely on hardware memory segment permissions for control/trapping.
However, it’s heavyweight to do on a per-request level. This is especially so in a world where process-per-request is already considered expensive.
Furthermore, if you are trying to run on cloud providers like EC2 instances (except bare metal), you won’t get hardware virtualization support, i.e. take advantage of Linux KVM. Hardware virtualization especially helps in its support for nested page tables (guest virtual —> guest physical —> host physical). This includes Firecracker (“microVMs”), which use KVM.
Operating system users
You can run things as different users. This is enough for a bunch of use cases.
However, there’s still a lot of information that is shared:
- Any user can always run
psto see what else is running on the system. - Any user can make network requests, for instance to other locally running servers.
- Users that create resources (such as files on disk, etc.) will need to be work defensively to ensure these are not accessible to others, as this is frequently not the default.
And other practical corncerns:
- It’s tedious and stateful to manage (to dynamically add and remove users). Consider doing this per request.
- You have a whole kernel surface area to protect against.
Containers also take advantage of some similar flavor of kernel-level protection, but allowing for less sharing.
Containers
Containers (namespaces) have historically been said not to be as secure as VMs. This is due to the kernel having a large surface area to attack. Any hole will render the entire machinery broken. There is disagreement here on the risk.
Papering over this, and assuming you’re OK with the track record of containers (more on mitigations later), you could always just run a bunch of containers. The container could be just a single process, serving a specific request.
Orchestrating containers on your own is an option, but a bit tedious to have to roll your own. A bit like writing your own process manager—you can hack-job it, but writing a robust one is annoying.
Kubernetes orchestrates containers. But its architecture means its various controller components are written with the control loop pattern. This prioritizes eventual convergence over latency—in practice, you’re commonly looking at at least a few seconds. So that would be noticeable overhead in all but the longest-running web requests.
Projects like Knative went to great lengths to get their startup times down. (source)
There’s also the issue of: what if you’re already running in a container? Like in a Docker runtime, or in Kubernetes—what do you do then? You could always delegate to the outer Docker, in typical DinD style. This of course means you’re back to doing your own container management. But more on this further down.
gvisor, kata-containers, etc.
The Kubernetes docs have a section on sandboxing, recommending gvisor. Gvisor is just an implementation of the kernel API in userspace—think wine, but for the Linux API in Linux. This lets you not need so much trust in securing the entire kernel surface area (for some overhead). So it helps in the “sandbox from host” use case, but doesn’t add anything to the “sandbox requests from each other” use case—you’re still spinning up a pod per request.
k8s also supports orchestrating VMs, with kata-containers. There has even been experimental support for firecracker, again assuming you’re running on bare metal. There are various infelicities due to impedance mismatch between the k8s API and firecracker APIs, however—source. I’ve seen other work here including firecracker via kata. Differentiating this area starts getting a little bit blurry to me.
Side notes: seccomp, eBPF, capabilities, and more
Often you’ll see seccomp mentioned in the same breath. Modern seccomp refers to eBPF. This is basically a way for you to filter what syscalls can be made by any process.
This is not quite directly relevant to the kind of per-request/fine-grained sandboxing we’re discussing here. This is about the conventional use case of sandboxing discussed in the past.
You can filter out a bunch of syscalls, but processes could still be running in the same environment, seeing each other, accessing the same shared resources, communicating. Unless you filter out all syscalls so that (for instance) it can do nothing at all—but there’s the tradeoff of how crippled you want your sandbox to be (in its legitimate uses).
However, filtering can greatly help reduce the kernel surface area, which is a concern with containers. Ideally, you can instrument your app to determine what syscalls it needs in normal operation, and permit only those. And you can do so after its bootup process (where it might be performing a bunch of syscalls that it subsequently not need), and right before you launch into user code. Note this much is impossible to do from the other systems.
Capabilities vs. eBPF? Capabilities are basically voluntary checks that specific syscalls make, as part of their implementations—they’re specific to the syscall, and you’re limited to whatever are the capabiltiies defined. eBPF filtering happens “before” the syscall logic executes. So they are more general, and have a smaller Trusted Computing Base.
There are various tools I haven’t looked deeply into that help with instrumentation/analysis to determine what seccomp filters you can impose:
(User) namespaces
Earlier we mentioned that you can orchestrate your own containers. But that’s tedious—what we really want is to just run some process, and have it be sandboxed. We don’t want to introduce any state to manage.
Recent Linux kernels support user namespaces, which can be nested up to 32 levels deep. User namespaces are special in that all other namespace types “belong” to user namespaces. So you can in fact run “containers within containers.”
The standard way to access these is via unshare(1) or unshare(2), setns(2), and another one I forget.
Tools like bubblewrap make this easier. Some other tools you might come across, which I found to be slightly off-the-mark:
- firejail: similar and commonly contrasted with bwrap, but has a bunch of baggage focusing on desktop applications.
- sandbox from Cloudflare: focuses on applying seccomp filters without access to source code.
- minijail: focuses on applying seccomp filters without access to source code. But also layers in namespaces and capabilities.
- mbox: does not add privacy by default, only prevents mutations.
- crabjail
- nsjail
Networking
In the above, I’ve mostly focused on sandboxing with respect to local resources. I’m ignoring things like unauthorized access of local network resources—even in your sandbox, if you have access to the network, you can try to reach hosts you’re not meant to.
TODO You can use userland networking stacks lwp.
Side note: privilege separation
TODO privsep
Server side Javascript
If you don’t need general-purpose sandboxing, you can consider techniques specific to your language/platform/runtime/etc. For instance, I was recently looking into this for Javascript/node.js.
But besides the fact that I was looking into it recently, other advances in the Javascript arena have made it interesting.
VM-specific techniques
If you survey some Stack Overflow questions:
- Safely sandbox and execute user submitted JavaScript?
- How to run user-submitted scripts securely in a node.js sandbox?
- How can I sandbox untrusted user-submitted JavaScript content?
- How to run untrusted code serverside?
You’ll find solutions offered that work within node.js, but they all have issues:
- vm: not meant to be a secure sandbox.
- jailed: leaky security track record.
- vm2: more secure, but still several escapes just this year
(And these track records are despite these tools not having received that many eyeballs.)
Another important aspect of these: you have to audit/define your own sandboxed environment.
Consider something like vm2. You can basically tell it to eval() some script, with access to the modules you bless. It does the job it says.
But say you want your user sandbox to do something relatively complex, not just evaluate some arithmetic or pure functions.
For instance, if you want it to be able to perform some React SSR, then you’re going to need to open up access to a bunch of modules.
It might need to fetch, use streams, run tools in util, etc.
Those functions could return complex objects themselves.
And any one of these handles could let the code access things that are outside its sandbox—all it needs is access to one fs module, one exec function, one eval, etc.
So you’ll need to audit everything it touches, deeply.
Or (more likely) you’ll need to construct your own secure shims for all these things, exposing the bare minimum functionality needed.
V8 Isolates
So far, we’ve talked about isolation that requires at least OS processes to work. But will this scale? This is probably good enough for a bunch of use cases. That’s how the old world ran, with CGI scripts forking per request.
Sadly, these days, fork is not smiled upon generally. That would help avoid certain startup costs.
In that sense, isolates are actually more secure than what most runtimes offer.
TODO But you still need to create your own secure environment.
Outsource
Of course, if you can do so, maybe you don’t have to think about this problem at all, and can delegate it out to someone else.
If you’re actually building a web application server, should we use something like Vercel or Netlify? Their “traditional” (non-edge) backends are built on AWS Lambda. Lambda runs on normal server instances, called execution environments. Multiple requests are served from the same environment, and thus they can end up sharing things and not be isolated.
But all modern edge-based runtimes are based on some flavor of V8 isolates. (Vercel’s is based on Cloudflare Workers, Netlify’s is based on Denoland.) There’s also Shopify Oxygen. It comes down to what kind of environment you want to provide to your user-run code—if it matches what the isolate-based environments give you, then great! And a number of them are purportedly trying to converge on some common denominator in the form of a standard edge runtime interface, WinterCG.
Resources
Follow me on Twitter for more ramblings.